The poor, misunderstood innerText
Few things are as misunderstood and misused on the web as 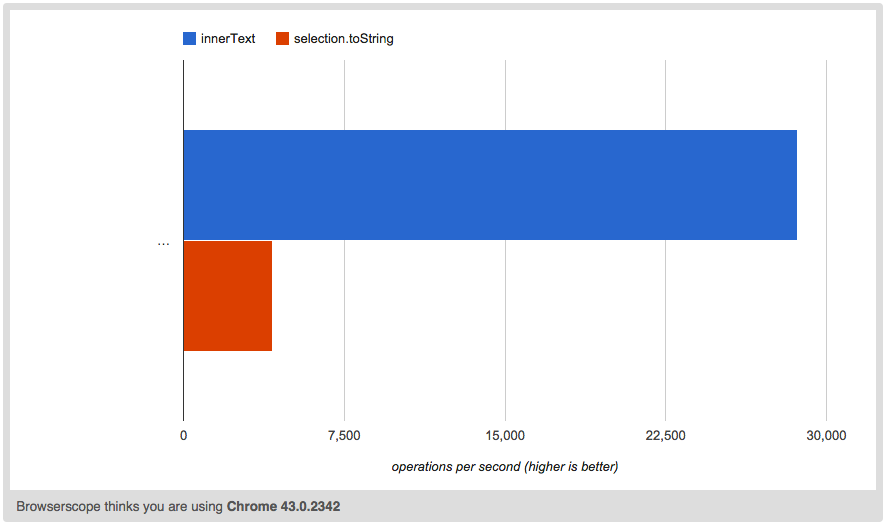 Internet Explorer got this right —
Internet Explorer got this right — 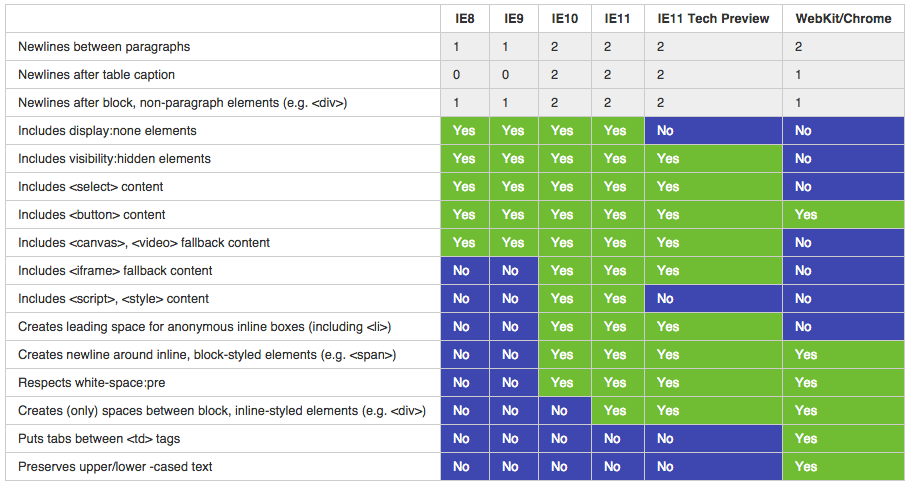 I started with (now extinct) [test suite by Aryeh Gregor](https://web.archive.org/web/20110205234444/http://aryeh.name/spec/innertext/test/innerText.html) and [added few more things](http://kangax.github.io/jstests/innerText/) to it. I also searched WebKit/Blink bug trackers and included [whatever](https://code.google.com/p/chromium/issues/detail?id=96839) [relevant](https://bugs.webkit.org/show_bug.cgi?id=14805) [things](https://bugs.webkit.org/show_bug.cgi?id=17830) I found there.
The table above (and in the test suite) shows all the gory details, but few things worth mentioning. First, good news — Internet Explorer <=9 are identical in their behavior :) Now bad — everything else diverges. Even IE changes with each new version — 9, 10, 11, and Tech Preview (the unreleased version of IE that's currently in the making) are all different. What's also interesting is how WebKit copied some of the old-IE traits — such as not including contents of <script> and <style> elements — and then when IE changed, they naturally drifted apart. Currently, some of the WebKit/Blink behavior is like old-IE and some isn't. But even comparing to original versions, WebKit did a poor job copying this feature, or rather, it seems like they've tried to make it better!
Unlike IE, WebKit/Blink insert tabs between table cells — that kind of makes sense! They also preserve upper/lower-cased text, which is arguably better. They don't include hidden elements ("display:none", "visibility:hidden"), which makes sense too. And they don't include contents of <select> elements and <canvas>/<video> fallback — perhaps a questionable aspect — but reasonable as well.
Ok, there's more good news.
Notice that IE Tech Preview (Spartan) is now much closer to WebKit/Blink. There's only 9 aspects they differ in (comparing to 10-11 in earlier versions). That's still a lot but there's at least some hope for convergence. Most notably, IE again stopped including <script> and <style> contents, and — for the first time ever — stopped including "display:none" elements (but not "visibility:hidden" ones — more on that later).
I started with (now extinct) [test suite by Aryeh Gregor](https://web.archive.org/web/20110205234444/http://aryeh.name/spec/innertext/test/innerText.html) and [added few more things](http://kangax.github.io/jstests/innerText/) to it. I also searched WebKit/Blink bug trackers and included [whatever](https://code.google.com/p/chromium/issues/detail?id=96839) [relevant](https://bugs.webkit.org/show_bug.cgi?id=14805) [things](https://bugs.webkit.org/show_bug.cgi?id=17830) I found there.
The table above (and in the test suite) shows all the gory details, but few things worth mentioning. First, good news — Internet Explorer <=9 are identical in their behavior :) Now bad — everything else diverges. Even IE changes with each new version — 9, 10, 11, and Tech Preview (the unreleased version of IE that's currently in the making) are all different. What's also interesting is how WebKit copied some of the old-IE traits — such as not including contents of <script> and <style> elements — and then when IE changed, they naturally drifted apart. Currently, some of the WebKit/Blink behavior is like old-IE and some isn't. But even comparing to original versions, WebKit did a poor job copying this feature, or rather, it seems like they've tried to make it better!
Unlike IE, WebKit/Blink insert tabs between table cells — that kind of makes sense! They also preserve upper/lower-cased text, which is arguably better. They don't include hidden elements ("display:none", "visibility:hidden"), which makes sense too. And they don't include contents of <select> elements and <canvas>/<video> fallback — perhaps a questionable aspect — but reasonable as well.
Ok, there's more good news.
Notice that IE Tech Preview (Spartan) is now much closer to WebKit/Blink. There's only 9 aspects they differ in (comparing to 10-11 in earlier versions). That's still a lot but there's at least some hope for convergence. Most notably, IE again stopped including <script> and <style> contents, and — for the first time ever — stopped including "display:none" elements (but not "visibility:hidden" ones — more on that later).
 In [this blog post](http://www.kellegous.com/j/2013/02/27/innertext-vs-textcontent/), Kelly Norton is talking about
In [this blog post](http://www.kellegous.com/j/2013/02/27/innertext-vs-textcontent/), Kelly Norton is talking about 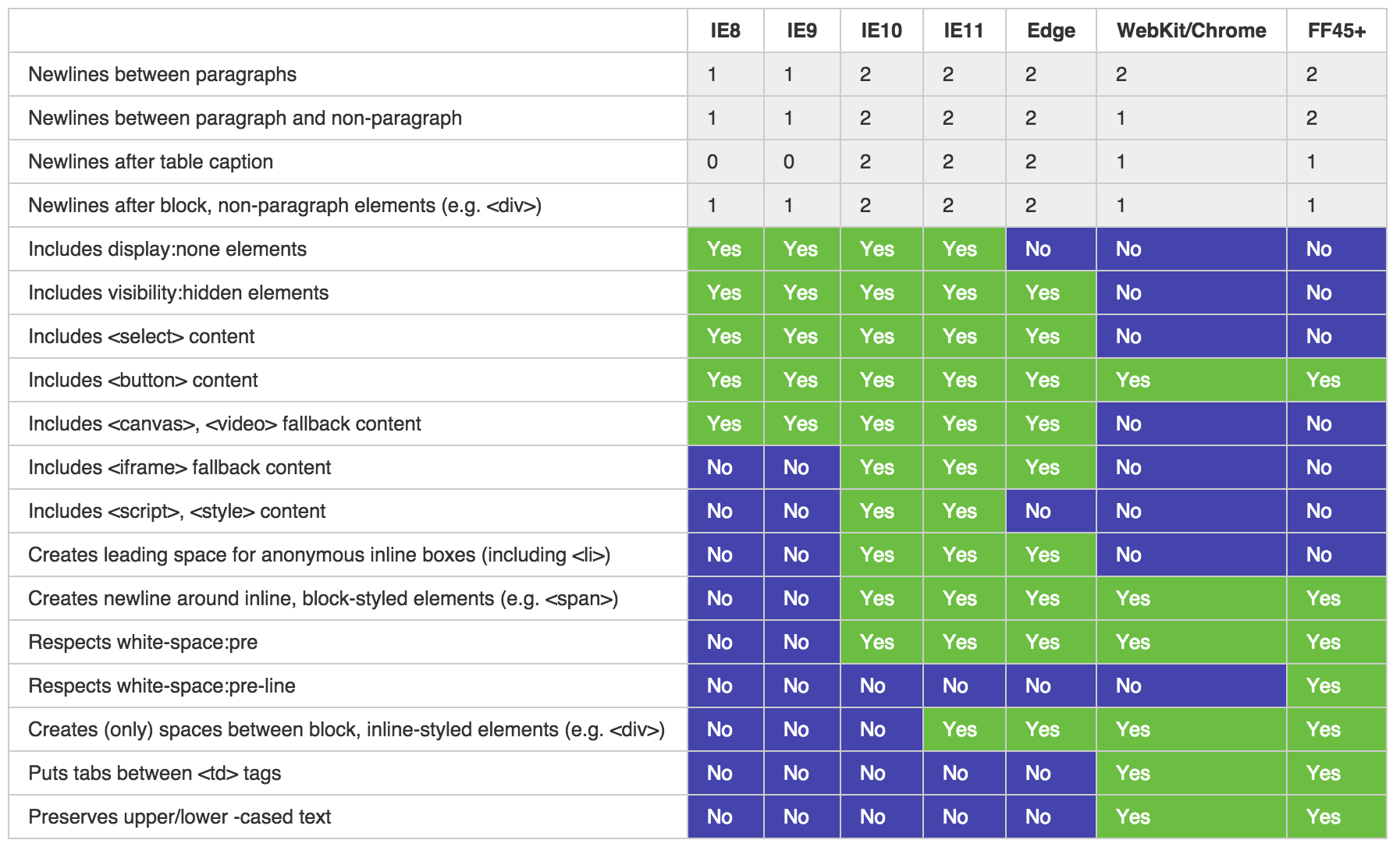 The spec already revealed few bugs in Chrome, which I'm hoping to file tickets for and see resolved. If we can then also get Edge to converge, we'll be very close to having all 3 biggest browsers behave similarly, making `innerText` viable feature in a near future.
The spec already revealed few bugs in Chrome, which I'm hoping to file tickets for and see resolved. If we can then also get Edge to converge, we'll be very close to having all 3 biggest browsers behave similarly, making `innerText` viable feature in a near future.
innerText property.
That quirky, non-standard way of element's text retrieval, [introduced by Internet Explorer](https://msdn.microsoft.com/en-us/library/ie/ms533899%28v=vs.85%29.aspx) and later "copied" by both WebKit/Blink and Opera for web-compatibility reasons. It's usually seen in combination with textContent — as a cross-browser way of using standard property followed by a proprietary one:
Or as the main webcompat offender in [numerous Mozilla tickets](https://bugzilla.mozilla.org/show_bug.cgi?id=264412#c24) — since Mozilla is one of the only major browsers refusing to add this non-standard property — when someone doesn't know what they're doing, skipping textContent "fallback" altogether:
innerText is pretty much always frown upon. After all, why would you want to use a non-standard property that does the "same" thing as a standard one? Very few people venture to actually check the differences, and on the surface it certainly appears as there is none. Those curious enough to investigate further usually do find them, but only slight ones, and only when retrieving text, not setting it.
Back in 2009, I did just that. And I even wrote [this StackOverflow answer](http://stackoverflow.com/a/1359822/130652) on the exact differences — slight whitespace deviations, things like inclusion of <script> contents by textContent (but not innerText), differences in interface (Node vs. HTMLElement), and so on.
All this time I was strongly convinced that there isn't much else to know about textContent vs. innerText. Just steer away from innerText, use this "combo" for cross-browser code, keep in mind slight differences, and you're golden.
Little did I know that I was merely looking at the tip of the iceberg and that my perception of innerText will change drastically. What you're about to hear is the story of Internet Explorer getting something right, the real differences between these properties, and how we probably want to standardize this red-headed stepchild.
The real difference
A little while ago, I was helping someone with the implementation of text editor in a browser. This is when I realized just how ridiculously important these seemingly insignificant whitespace deviations betweentextContent and innerText are.
Here's a simple example:
See the Pen gbEWvR by Juriy Zaytsev (@kangax) on CodePen.
Notice howinnerText almost precisely represents exactly how text appears on the page. textContent, on the other hand, does something strange — it ignores newlines created by <br> and around styled-as-block elements (<span> in this case). But it preserves spaces as they are defined in the markup. What does it actually do?
Looking at the [spec](http://www.w3.org/TR/2004/REC-DOM-Level-3-Core-20040407/core.html#Node3-textContent), we get this:
This attribute returns the text content of this node and its descendants. [...]In other words,
On getting, no serialization is performed, the returned string does not contain any markup. No whitespace normalization is performed and the returned string does not contain the white spaces in element content (see the attribute Text.isElementContentWhitespace). [...]
The string returned is made of the text content of this node depending on its type, as defined below:
For ELEMENT_NODE, ATTRIBUTE_NODE, ENTITY_NODE, ENTITY_REFERENCE_NODE, DOCUMENT_FRAGMENT_NODE:
concatenation of the textContent attribute value of every child node, excluding COMMENT_NODE and PROCESSING_INSTRUCTION_NODE nodes. This is the empty string if the node has no children.
For TEXT_NODE, CDATA_SECTION_NODE, COMMENT_NODE, PROCESSING_INSTRUCTION_NODE
nodeValue
textContent returns concatenated text of all text nodes. Which is almost like taking markup (i.e. innerHTML) and stripping it off of the tags. Notice that no whitespace normalization is performed, the text and whitespace are essentially spit out the same way they're defined in the markup. If you have a giant chunk of newlines in HTML source, you'll have them as part of textContent as well.
While investigating these issues, I came across a [fantastic blog post by Mike Wilcox](http://clubajax.org/plain-text-vs-innertext-vs-textcontent/) from 2010, and pretty much the only place where someone tries to bring attention to this issue. In it, Mike takes a stab at the same things I'm describing here, saying these true-to-the-bone words:
Internet Explorer implemented innerText in version 4.0, and it’s a useful, if misunderstood feature. [...]Knowing these differences, we can see just how potentially misleading (and dangerous) a typical
The most common usage for these properties is while working on a rich text editor, when you need to “get the plain text” or for other functional reasons. [...]
Because “no whitespace normalization is performed”, what textContent is essentially doing is acting like a PRE element. The markup is stripped, but otherwise what we get is exactly what was in the HTML document — including tabs, spaces, lack of spaces, and line breaks. It’s getting the source code from the HTML! What good this is, I really don’t know.
textContent || innerText retrieval is. It's pretty much like saying:
The case for innerText
Coming back to a text editor... Let's say we have a [contenteditable](http://html5demos.com/contenteditable) area in which a user is writing something. And we'd like to have our own spelling correction of a text in that area. In order to do that, we really want to analyze text the way it appears in the browser, not in the markup. We'd like to know if there are newlines or spaces typed by a user, and not those that are in the markup, so that we can correct text accordingly. This is just one use-case of plain text retrieval. Perhaps you might want to convert written text to another format (PDF, SVG, image via canvas, etc.) in which case it has to look exactly as it was typed. Or maybe you need to know the cursor position in a text (or its entire length), so you need to operate on a text the way it's presented. I'm sure there's more scenarios. A good way to think aboutinnerText is as if the text was selected and copied off the page. In fact, this is exactly what WebKit/Blink does — it [uses the same code](http://lists.w3.org/Archives/Public/public-html/2011Jul/0133.html) for Selection#toString serialization and innerText!
Speaking of that — if innerText is essentially the same thing as stringified selection, shouldn't it be possible to emulate it via Selection#toString?
It sure is, but as you can imagine, the performance of such thing [leaves more to be desired](http://jsperf.com/innertext-vs-selection-tostring/4) — we need to save current selection, then change selection to contain entire element contents, get string representation, then restore original selection:
The problems with this frankenstein of a workaround are performance, complexity, and clarity. It shouldn't be so hard to get "plain text" representation of an element. Especially when there's an already "implemented" property that does just that.
Internet Explorer got this right — textContent and Selection#toString are poor contenders in cases like this; innerText is exactly what we need. Except that it's non-standard, and unsupported by one major browser. Thankfully, at least Chrome (Blink) and Safari (WebKit) were considerate enough to immitate it. One would hope there's no deviations among their implementations. Or is there?
Differences with textContent
Once I realized the significance ofinnerText, I wanted to see the differences among 2 engines. Since there was nothing like this out there, I set on a path to explore it. In true ["cross-browser maddness" traditions](http://unixpapa.com/js/key.html), what I've found was not for the faint of heart.
I started with (now extinct) [test suite by Aryeh Gregor](https://web.archive.org/web/20110205234444/http://aryeh.name/spec/innertext/test/innerText.html) and [added few more things](http://kangax.github.io/jstests/innerText/) to it. I also searched WebKit/Blink bug trackers and included [whatever](https://code.google.com/p/chromium/issues/detail?id=96839) [relevant](https://bugs.webkit.org/show_bug.cgi?id=14805) [things](https://bugs.webkit.org/show_bug.cgi?id=17830) I found there.
The table above (and in the test suite) shows all the gory details, but few things worth mentioning. First, good news — Internet Explorer <=9 are identical in their behavior :) Now bad — everything else diverges. Even IE changes with each new version — 9, 10, 11, and Tech Preview (the unreleased version of IE that's currently in the making) are all different. What's also interesting is how WebKit copied some of the old-IE traits — such as not including contents of <script> and <style> elements — and then when IE changed, they naturally drifted apart. Currently, some of the WebKit/Blink behavior is like old-IE and some isn't. But even comparing to original versions, WebKit did a poor job copying this feature, or rather, it seems like they've tried to make it better!
Unlike IE, WebKit/Blink insert tabs between table cells — that kind of makes sense! They also preserve upper/lower-cased text, which is arguably better. They don't include hidden elements ("display:none", "visibility:hidden"), which makes sense too. And they don't include contents of <select> elements and <canvas>/<video> fallback — perhaps a questionable aspect — but reasonable as well.
Ok, there's more good news.
Notice that IE Tech Preview (Spartan) is now much closer to WebKit/Blink. There's only 9 aspects they differ in (comparing to 10-11 in earlier versions). That's still a lot but there's at least some hope for convergence. Most notably, IE again stopped including <script> and <style> contents, and — for the first time ever — stopped including "display:none" elements (but not "visibility:hidden" ones — more on that later).
Opera mess
You might have caught the lack of Opera in a table. It's not just because Opera is now using Blink engine (essentially having WebKit behavior). It's also due to the fact that when it wasn't on Blink, it's been reaaaally naughty when it comes toinnerText. To sustain web compatibility, Opera simply went ahead and "aliased" innerText to textContent. That's right, in Opera, innerText would return nothing close to what we see in IE or WebKit. There's simply no point including in a table; it would diverge in every single aspect, and we can just consider it as never implemented.
Note on performance
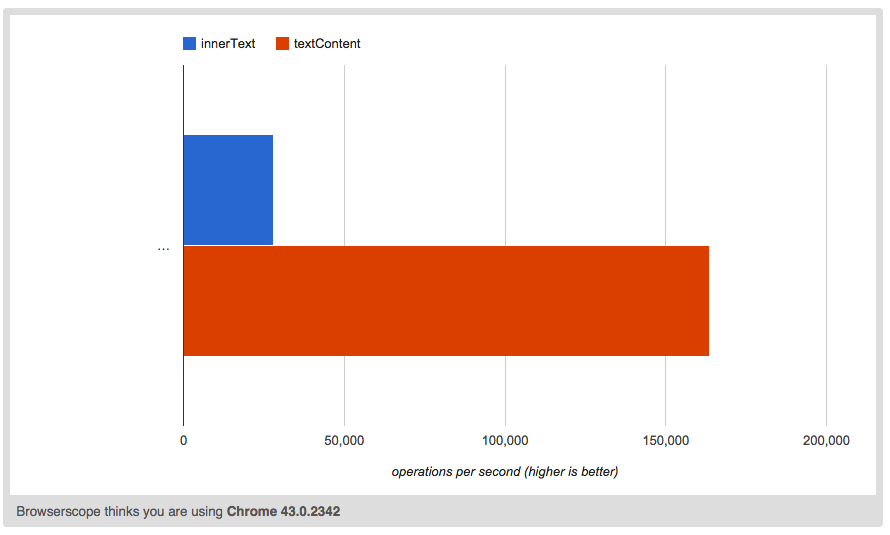
Another difference lurks behindtextContent and innerText — performance.
You can find dozens of [tests on jsperf.com comparing innerText and textContent](http://jsperf.com/search?q=innerText) — innerText is often dozens time slower.
In [this blog post](http://www.kellegous.com/j/2013/02/27/innertext-vs-textcontent/), Kelly Norton is talking about innerText being up to 300x slower (although that seems like a particularly rare case) and advises against using it entirely.
Knowing the underlying concepts of both properties, this shouldn't come as a surprise. After all, innerText requires knowledge of layout and [anything that touches layout is expensive](http://gent.ilcore.com/2011/03/how-not-to-trigger-layout-in-webkit.html).
So for all intents and purposes, innerText is significantly slower than textContent. And if all you need is to retrieve a text of an element without any kind of style awareness, you should — by all means — use textContent instead. However, this style awareness of innerText is exactly what we need when retrieving text "as presented"; and that comes with a price.
What about jQuery?
You're probably familiar with jQuery'stext() method. But how exactly does it work and what does it use — textContent || innerText combo or something else? Turns out, jQuery [takes a safe route](https://github.com/jquery/jquery/blob/7602dc708dc6d9d0ae9982aadb9fa4615a9c49fa/external/sizzle/dist/sizzle.js#L942-L971) — it either returns textContent (if available), or manually does what textContent is supposed to do — iterates over all children and concatenates their nodeValue's. Apparently, at one point jQuery **did** use innerText, but then [ran into good old whitespace differences](http://bugs.jquery.com/ticket/11153) and decided to ditch it altogether.
So if we wanted to use jQuery to get real text representation (à la innerText), we can't use jQuery's text() since it's basically a cross-browser textContent. We would need to roll our own solution.
Standardization attempts
Hopefully by now I've convinced you thatinnerText is pretty damn useful; we went over the underlying concept, browser differences, performance implications and saw how even an all-mighty jQuery is of no help.
You would think that by now this property is standardized or at least making its way into the standard.
Well, not so fast.
Back in 2010, Adam Barth (of Google), [proposes to spec innerText](http://lists.w3.org/Archives/Public/public-whatwg-archive/2010Aug/0455.html) in a WHATWG mailing list. Funny enough, all Adam wants is to set pure text (not markup!) of an element in a secure way. He also doesn't know about textContent, which would certainly be a preferred (standard) way of doing that. Fortunately, Mike Wilcox, whose blog post I mentioned earlier, chimes in with:
In addition to Adam's comments, there is no standard, stable way of *getting* the text from a series of nodes. textContent returns everything, including tabs, white space, and even script content. [...] innerText is one of those things IE got right, just like innerHTML. Let's please consider making that a standard instead of removing it.In the same thread, Robert O'Callahan (of Mozilla) [doubts usefulness of innerText](http://lists.w3.org/Archives/Public/public-whatwg-archive/2010Aug/0477.html) but also adds:
But if Mike Wilcox or others want to make the case that innerText is actually a useful and needed feature, we should hear it. Or if someone from Webkit or Opera wants to explain why they added it, that would be useful too.Ian Hixie is open to adding it to a spec if it's needed for web compatibility. While Rob O'Callahan considers this a redundant feature, Maciej Stachowiak (of WebKit/Apple) hits the nail on the head with [this fantastic reply](http://lists.w3.org/Archives/Public/public-whatwg-archive/2010Aug/0480.html):
Is it a genuinely useful feature? Yes, the ability to get plaintext content as rendered is a useful feature and annoying to implement from scratch. To give one very marginal data point, it's used by our regression text framework to output the plaintext version of a page, for tests where layout is irrelevant. A more hypothetical use would be a rich text editor that has a "convert to plaintext" feature. textContent is not as useful for these use cases, since it doesn't handle line breaks and unrendered whitespace properly.To which Rob gives a reasonable reply:
[...]
These factors would tend to weigh against removing it.
There are lots of ways people might want to do that. For example, "convert to plaintext" features often introduce characters for list bullets (e.g. '*') and item numbers. (E.g., Mac TextEdit does.) Safari 5 doesn't do either. [...] Satisfying more than a small number of potential users with a single attribute may be difficult.And the conversation dies out.
Is innerText really useful?
As Rob points out, "convert to plaintext" could certainly be an ambiguous task. In fact, we can easily create a test markup that looks nothing like its "plain text" version:See the Pen emXMKZ by Juriy Zaytsev (@kangax) on CodePen.
Notice that "opacity: 0" elements are not displayed, yet they are part ofinnerText. Ditto with infamous "text-indent: -999px" hiding technique. The bullets from the list are not accounted for and neither is dynamically generated content (via ::after pseudo selector). Paragraphs only create 1 newline, even though in reality they could have gigantic margins.
But I think that's OK.
If you think of innerText as text copied from the page, most of these "artifacts" make perfect sense. Just because a chunk of text is given "opacity: 0" doesn't mean that it shouldn't be part of output. It's a purely presentational concern, just like bullets, space between paragraphs or indented text. What matters is **structural preservation** — block-styled elements should create newlines, inline ones should be inline.
One iffy aspect is probably "text-transform". Should capitalized or uppercased text be preserved? WebKit/Blink think it should; Internet Explorer doesn't. Is it part of a text itself or merely styling?
Another one is "visibility: hidden". Similar to "opacity: 0" (and unlike "display: none"), a text is still part of the flow, it just can't be seen. Common sense would suggest that it should still be part of the output. And while Internet Explorer does just that, WebKit/Blink disagrees (also being curiously inconsistent with their "opacity: 0" behavior).
Elements that aren't known to a browser pose an additional problem. For example, WebKit/Blink recently started supporting <template> element. That element is not displayed, and so it is not part of innerText. To Internet Explorer, however, it's nothing but an unknown inline element, and of course it outputs its contents.
Standardization, take 2
In 2011, anotherinnerText proposal [is posted to WHATWG mailing list](http://lists.w3.org/Archives/Public/public-html/2011Jul/0133.html), this time by Aryeh Gregor. Aryeh proposes to either:
- Drop
innerTextentirely - Spec
innerTextto be liketextContent - Actually spec
innerTextaccording to whatever IE/WebKit are doing
innerText:
The problem with (3) is that it would be very hard to spec; it would be even harder to spec in a way that all browsers can implement; and any spec would probably have to be quite incompatible anyway with the existing implementations that follow the general approach. [...]Indeed, as we've seen from the tests, compatibility poses to be a serious issue. If we were to standardize
innerText, which of the 2 behaviors should we put in a spec?
Another problem is reliance on Selection.toString() (as expressed by Boris Zbarsky):
It's not clear whether the latter is in fact an option; that depends on how Selection.toString gets specified and whether UAs are willing to do the same for innerText as they do for Selection.toString....In the end, we're left with [this WHATWG ticket by Aryeh](https://www.w3.org/Bugs/Public/show_bug.cgi?id=13145) on specifying
So far the only proposal I've seen for Selection.toString is "do what the copy operation does", which is neither well-defined nor acceptable for innerText. In my opinion.
innerText. Things look rather grim, as evidenced in one of the comments:
I've been told in no uncertain terms that it's not practical for non-Gecko browsers to remove. Depending on the rendering tree to the extent WebKit does, on the other hand, is insanely complicated to spec in terms of standard stuff like DOM and CSS. Also, it potentially breaks for detached nodes (WebKit behaves totally differently in that case). [...] But Gecko people seemed pretty unhappy about this kind of complexity and rendering dependence in a DOM property. And on the other hand, I got the impression WebKit is reluctant to rewrite their innerText implementation at all. So I'm figuring that the spec that will be implemented by the most browsers possible is one that's as simple as possible, basically just a compat shim. If multiple implementers actually want to implement something like the innerText spec I started writing, I'd be happy to resume work on it, but that wasn't my impression.We can't remove it, can't change it, can't spec it to depend on rendering, and spec'ing it would be quite difficult :)
Light at the end of a tunnel?
Could there still be some hope forinnerText or will it forever stay an unspecified legacy with 2 different implementations?
My hope is that the test suite and compatibility table are the first step in making things better. We need to know exactly how engines differ, and we need to have a good understanding of what to include in a spec. I'm sure this doesn't cover all cases, but it's a start (other aspects worth exploring: shadow DOM, detached nodes).
I think this test suite should be enough to write 90%-complete spec of innerText. The biggest issue is deciding which behavior to choose among IE and WebKit/Blink.
The plan could be:
1. Write a spec
2. Try to converge IE and WebKit/Blink behavior
3. Implement spec'd behavior in Firefox
Seeing [how amazing Microsoft has been](https://status.modern.ie/) recently, I really hope we can make this happen.
The naive spec
I took a stab at a relatively simple version ofinnerText:
Couple important tasks here:
1. Checking if a text node is within "formatted" context (i.e. a child of "white-space: pre-*" node), in which case its contents should be concatenated as is; otherwise collapse all whitespaces to 1.
2. Checking if a node is block-styled ("block", "list-item", "table", etc.), in which case it has to be surrounded by newlines; otherwise, it's inline and its contents are output as is.
Then there's things like ignoring <script>, <style>, etc. nodes and inserting tab ("\t") between <td> elements (to follow WebKit/Blink lead).
This is still a very minimal and naive implementation. For one, it doesn't collapse newlines between block elements — a quite important aspect. In order to do that, we need to keep track of more state — to know information about previous node's style. It also doesn't normalize whitespace in "true" manner — a text node with leading and trailing spaces, for example, should have those spaces stripped if it is (the only node?) in a block element.
This needs more work, but it's a decent start.
It would be also a good idea to write innerText implementation in Javascript, with unit tests for each of the "feature" in a compat table. Perhaps even supporting 2 modes — IE and WebKit/Blink. An implementation like this could then be simply integrated into non-supporting engines (or used as a proper polyfill).
I'd love to hear your thoughts, ideas, experiences, criticism. I hope (with all of your help) we can make some improvement in this direction. And even if nothing changes, at least some light was shed on this very misunderstood ancient feature.
Update: half a year later
It's been half a year since I wrote this post and few things changed for the better! First of all, [Robert O'Callahan](http://robert.ocallahan.org/) of Mozilla made some awesome effort — he decided to [spec out the innerText](https://github.com/rocallahan/innerText-spec) and then implemented it in Firefox. The idea was to create something simple but sensible. The proposed spec — only after about 11 years — is now [implemented in Firefox 45](https://bugzilla.mozilla.org/show_bug.cgi?id=264412) :) I've added FF45 results to [a compat table](http://kangax.github.io/jstests/innerText/) and aside from couple differences, FF is pretty close to Chrome's implementation. I'm also planning to add more tests to find any other differences among Chrome, FF, and Edge.
The spec already revealed few bugs in Chrome, which I'm hoping to file tickets for and see resolved. If we can then also get Edge to converge, we'll be very close to having all 3 biggest browsers behave similarly, making `innerText` viable feature in a near future.
Did you like this? Donations are welcome
comments powered by Disqus